Java面试Q&A

线程安全
Java内存模型
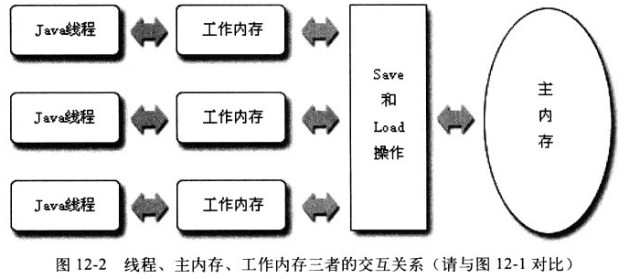
- 主内存:硬件的内存,所有变量均存储在主内存
- 工作内存:保存了被该内存使用的变量的主内存副本拷贝,线程对变量的所有操作都必须在工作内存中进行,而不能直接读写主内存的变量,线程间无法访问彼此的工作内存中的变量,线程间变量值的传递需要通过主内存来完成
线程安全
- CPU读取数据的优先级:寄存器>高速缓存>工作内存
- 缓存:线程耗费CPU读取数据进行计算时,有些数据被频繁读取而存储在寄存器和高速缓存中,当计算完毕时需要将寄存器和高速缓存的数据写回工作内存中
- 多线程造成的数据不一致:多线程同时读写某个拷贝主内存的工作内存数据时,由于线程之间的数据时不可见的,因此可能会产生寄存器-高速缓存-内存的数据同步问题,则可能产生数据不一致的线程安全问题
线程安全问题原因
造成线程安全问题主要是线程操作不满足三个特性:原子性、可见性、有序性
原子性(Atomicity)
线程操作不能被线程调度机制中断,要么全部执行完毕,要么全部不执行
Java内存模型确保基本数据的访问大都是原子操作
1
2
3
4x=10; //原子操作,直接将主内存的拷贝数值10写入工作内存中
y=x; //非原子操作,可拆分为两个指令:1.读取x指向的工作内存的值 2.将x的值写入工作内存y指向的内存中
x++; //非原子操作,可拆分为三个指令: 1.读取x指向的工作内存的值 2.进行加1操作 3.写入x指向的工作内存中
x=x+1; //非原子操作,同上可见性(Visibility)
线程对共享变量进行修改后,其他线程在读取变量前,从主内存同步别的线程的工作内存的共享变量的最新值,然后再将主内存中变量的最新值读取到自己的工作内存中
Java提供了关键字volatile来保证变量的可见性,
Java提供了关键字synchronized来保证变量的可见性,采用锁机制实现
有序性(Ordering)
程序执行的顺序按照代码先后顺序执行
编译器、处理器为了提高性能会将指令重新排序,指令重排不会影响到单线程程序执行结果,但会影响到多线程并发执行的程序的正确性
解决线程安全问题的方法
关键字volatile
volatile修饰的变量保证了可见性和有序性,轻量级多线程同步机制,不会引起上下文切换和线程调度, 用volatile修饰的变量,对其执行相关操作时,生成的汇编编码会多出一个lock前缀指令,lock前缀指令相当于一个内存屏障,可以保证以下特性
保证可见性:强制将对缓存修改的操作写入主内存中,可以保证修改的值会立即更新到主内存。如果是写操作,会导致其他CPU的缓存无效,其他线程读取变量会跳过CPU Cache去主内存中Load变量的最新值
保证有序性:可以确保前面的指令执行完毕才执行当前指令,也可以确保不会把后面的指令重排到当前指令前
关键字synchronized
synchronized关键字一般修饰存在共享数据操作的方法或者代码块,当多个线程同时操作共享数据时,采取互斥的规则保证同一时刻有且只有一个线程在操作共享数据,阻塞其余线程,利用加锁实现线程安全,保证了原子性、可见性、有序性,一般有三种应用方式
- 修饰实例(非静态)方法:给当前实例加锁,对同类不同实例的线程则无效,是实例锁
- 修饰静态方法:给当前类加锁,对同类不同实例的线程有效,是类锁
- 修饰代码块:指定加锁对象(如this),给当前类对象加锁,对同类不同实例的线程有效,是类锁
JVM中实例对象和Monitor
对象被存储在堆内存中,由以下形式存储
对象头:占有2个机器码(数组对象为3个字节码)
- 第一个机器码-Mark Word:非固定的数据结构,存储对象自身运行的数据,如HashCode、GC分代年龄、锁状态标识、锁标志位、偏向线程ID等
- 第二个机器码-类型指针:指向对象的类的原数据,JVM通过这个指针确定对象是哪个类的实例
- (第三个机器码-数组长度:记录数组长度)
实例数据:存放类的属性数据信息
- 对齐填充:JVM要求对象起始地址必须为8字节整数倍,用于填充多余空间字段
了解了对象存储形式后,我们来看synchronized锁是如何实现的,锁在对象中是以锁记录+对象头的引用指针,synchronized锁在对象头的MarkWord的锁标志位为10+对象头的引用指针指向monitor(管程),每个对象均有唯一的monitor与它相关,因此线程就是通过获取对象的monitor来锁定对象,从而阻塞其余线程对对象的操作,达到线程安全
锁状态
共有四种(2bit),无状态锁-偏向锁-轻量级锁-重量级锁
偏向锁:用于无锁竞争环境,减少同一线程获取锁的代价,同一线程频繁获取锁无需做任何同步操作、锁申请操作即可获取锁,提高性能
轻量级锁:用于线程交替执行同步块环境,若存在线程并发同时访问同一锁则升级为重量级锁
(自旋锁):介于轻量级锁与重量级锁之间,线程获取轻量级锁失败后不会立即挂起,而是进行自旋锁,让其进行几个空循环再获取一次锁,若得到锁则进入临界区操作共享数据,若还不能得到锁则只能挂起
重量级锁:如synchronized锁,保证同一时间有且只有一个线程能对共享内存进行操作
数据库索引
索引定义(MySQL):索引(Index)是帮助MySQL高效获取数据的数据结构
为何需要索引:数据库查询速度是衡量数据库效率的一个标准,因此数据库数据库系统设计者会从查询的角度优化数据库,这无非有两种方向,算法和数据结构,查询算法如顺序查找(数据有序 且O(n))、二分查找(数据有序且O(log2n))、二叉树查找(依托于树的数据结构),均依托于特殊的数据结构,但是数据库中的数据存储肯定是以空间效率高的形式存储,不可能因为查找方便而改变数据存储结构,因此数据库系统还维护着满足特定查找算法的数据结构——索引,索引以某种方式引用(关联)数据,在索引上使用高级查找算法提高查询数据的效率
索引数据结构:考虑到树的查询效率高并且可以保持有序,数据库索引采取树结构是十分合适的,二叉查找树查询的时间复杂度为O(log2n),查询速度和比较次数是最优的,但是由于数据库索引是存储在磁盘上的,设计到磁盘IO读写问题,而大数据的索引十分大不能全部加载到磁盘中,只能通过逐一加载磁盘页来加载索引的树节点,由于索引树的高度就是磁盘IO次数(B+树,B树由于中间节点有数据因此磁盘IO次数处于[0-树的高度]),二叉查找树高度过高(每个节点只有一条数据),因此我们需要一种高度较低的树作为索引的数据结构以减少磁盘IO次数,B树这种多路平衡查找树满足我们的要求
B-树:是一种多路平衡查找树,它的节点最多包含(关联)M个字节点,M也称为B-树的阶(度),M的大小取决于磁盘页的大小
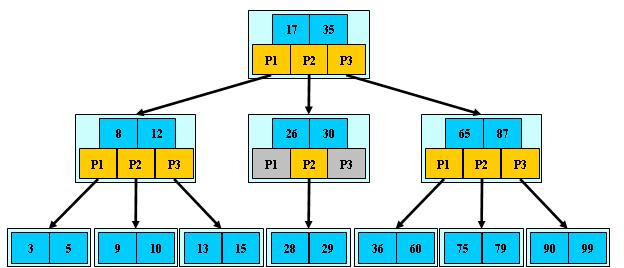
- B-树的规则:B-树的节点需要满足一定的规则,才能保证其平衡的特性
- 节点由元素和子节点指针交替排序而成,即指针数=元素数+1
- 根节点至少有两个子节点
- 中间节点都包含K-1个元素和K个子节点,满足M/2<=K<=M
- 叶子节点都包含K-1个元素,满足M/2<=K<=M
- 所有叶子节点处于同一深度
- 所有节点元素从小到大排列
- 查找规则:在节点中查找关键字,若无则根据大小规则查找子节点指针,在子节点中重复查找关键字,直到查找到叶子节点
- 插入规则:将节点根据大小规则插入到子节点中,若子节点元素数量为M,则节点分裂,分裂规则为:以M/2向下取整为基准元素,[0,(M/2)-1]的元素留在原子节点,[(M/2)+1,M-1]的元素分裂成新的子节点,M/2的基准元素插入到父节点中
- 删除规则:
- 非叶子结点删除第i个节点,则将节点的第i个子树中的最小值上移至删除元素的位置。
- 叶子节点删除元素,若删除后节点数量仍大于M/2,则直接删除
- 叶子节点删除元素,若删除后节点数量为(M/2)-1,则将兄弟节点中最近的节点上移至父节点,父节点中最接近叶子结点的元素下移至叶子节点,若兄弟节点元素由于上移节点数量为(M/2)-1,则将叶子结点和父节点中最接近叶子结点的元素均移动到兄弟节点
- B-树的规则:B-树的节点需要满足一定的规则,才能保证其平衡的特性
B+树:是B-树变种的平衡多路查找树,但B+树的查询性能比B-树更高,MySql数据库系统使用的索引就是B+树
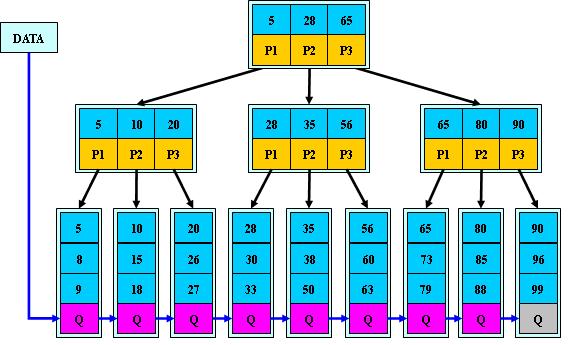
- M阶B+树的规则:
- 中间节点由元素和子节点指针一对一组成,即(M/2)-1<=指针数=元素数<=M-1
- 中间节点不包含数据,所有数据出现在叶子节点中,因此中间节点的元素对应的指针指向关键字大于等于自身的子节点
- 所有叶子节点多了链指针,因此可以区域查询
- 插入与删除与B-树大同小异
- 优点:相对于B-树,B+树更适合文件系统和数据库系统:
- 中间节点不存储数据只是索引,因此可以存储更多索引,磁盘IO次数减少
- 查询性能稳定(磁盘IO次数均为树的高度)
- 范围查询简便
- M阶B+树的规则:
哈希索引:采用一定的哈希算法,把键值换算成新的哈希值 ,检索时只需一次哈希算法即可定位到数据位置
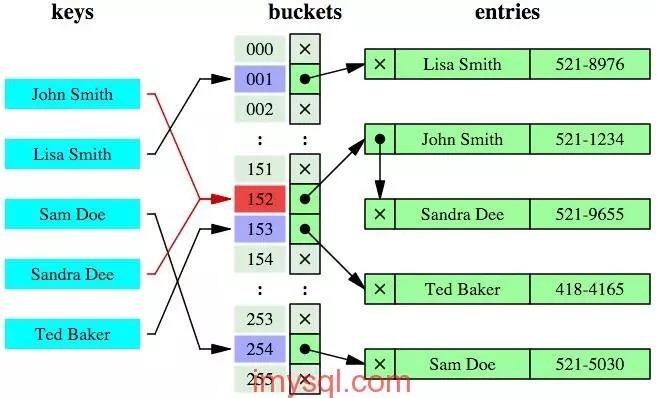
- 哈希索引的不足:无法通过索引进行排序,重复键造成检索效率降低(哈希碰撞),不支持范围查询(仅仅能满足“=”,“IN”,“<=>”查询 ),不能利用联合索引键查询
MySQL索引实现:MySQL中常用的索引引擎是MyISAM和InnoDB,使用的索引数据结构均是B+树,但是实际实现方式有所不同
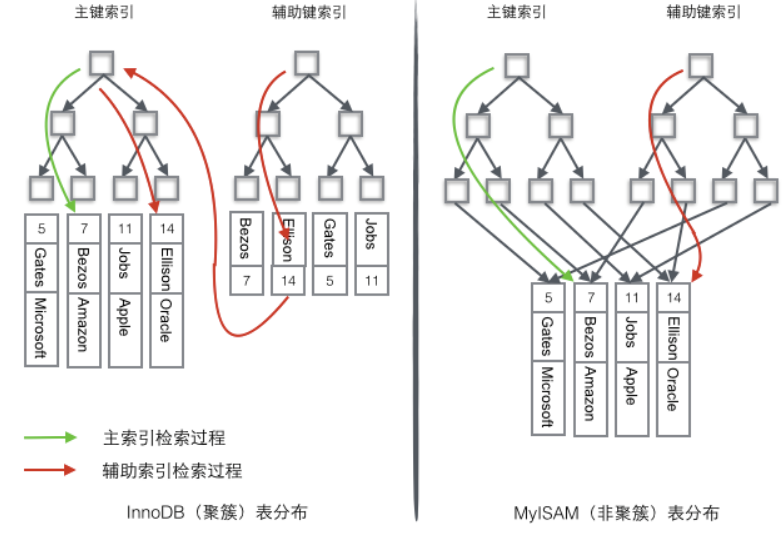
- InnoDB:使用的是聚簇索引,数据引擎本身就是索引文件,主键索引的叶子节点直接存储数据,辅助键索引的叶子节点存储主键索引值,因此使用辅助键查询数据需要先查询辅助键索引获取主键再查询主键索引获取数据,查询性能没有MyISAM引擎高
- MyISAM:使用的是非聚簇索引 ,即无论是主键索引还是辅助键索引的叶子节点均是存储数据所在的地址值,因此查询性能高,由于辅助键索引不依赖于主键索引,辅助键索引可以直接获取查询数据
- 使用场景:MyISAM适合不需要事务支持、高性能的场景,InnoDB适合需要事务支持、高并发(支持行锁)的场景
- MEMORY:值得注意的是,MySQL中还有一种引擎MEMORY,它默认使用哈希索引,而且数据存在内存中,因此数据读写性能十分高,但是安全性较低,只应用在小规模数据库中
Http长连接/短连接
异步/同步和阻塞/非阻塞
异步、同步、阻塞、非阻塞都是IO(输入输出)有关的概念