本文主要记录《Sklearn与TensorFlow 机器学习实用指南》中的理论知识拓展和实践问题中解决方案的总结

大纲
机器学习概念
机器学习是让计算机具有学习的能力,无需进行明确编程。 —— 亚瑟·萨缪尔,1959
计算机程序利用经验 E 学习任务 T,性能是 P,如果针对任务 T 的性能 P 随着经验 E 不断增长,则称为机器学习。 —— 汤姆·米切尔,1997
机器学习特点
- 需要手工调整或者长串规则才能解决的问题,机器学习算法可以简化代码、提高性能,如基于某些规则过滤垃圾邮件
- 传统方法难以解决的复杂问题,机器学习算法可以找到解决方案,如自我学习算法分辩语言、语音
- 洞察复杂问题和大量数据,机器学习算法可以挖掘数据中不显著的规律,如预测回归、分类数据等
监督/非监督学习
根据训练数据是否有标签(labels)可分为监督学习、非监督学习、半监督学习、强化学习
- 监督学习:训练算法的训练数据中包含标签,如
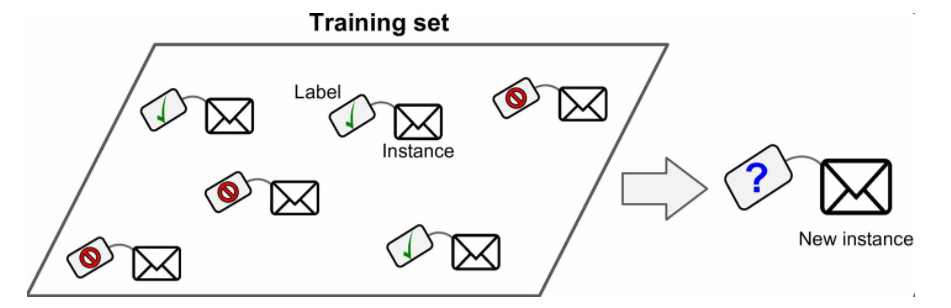
分类(垃圾邮件分类) 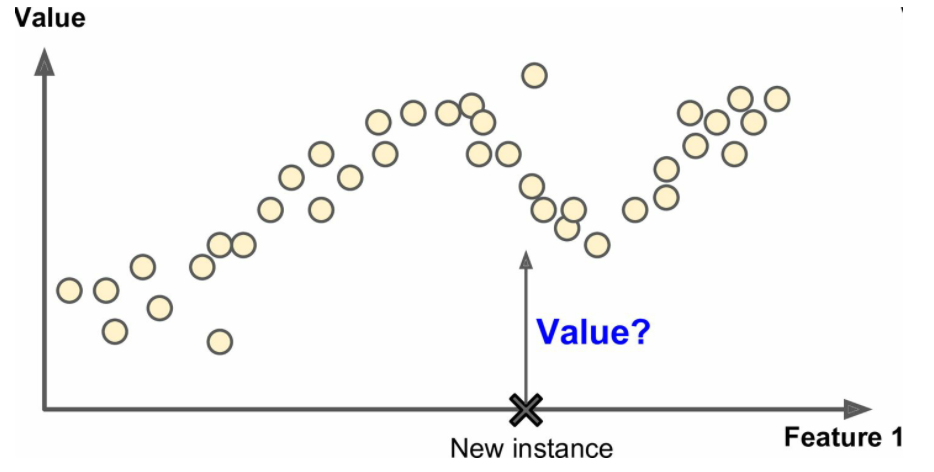
回归(预测目标数值)
重要的监督学习算法:KNN(分类)、线性回归(预测)、逻辑回归(分类)、支持向量机(SVM,分类)、决策树和随机森林(分类)、神经网络 - 非监督学习:训练算法的数据中不包含标签,如
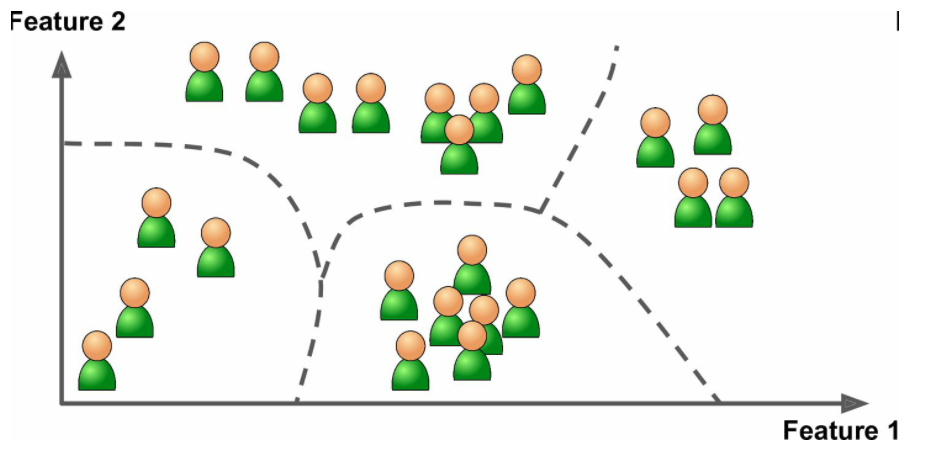
聚类 
可视化/降维 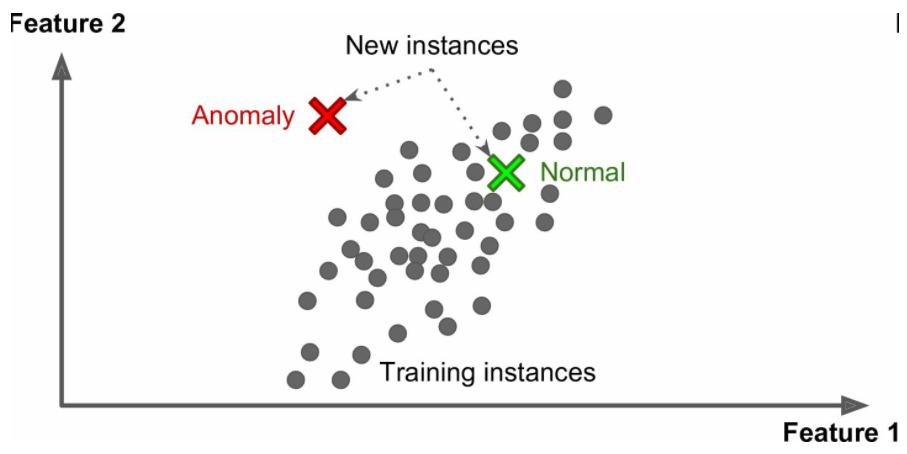
异常检测
重要的非监督学习算法:K-Means(聚类),层次聚类分析(HCA,聚类),主成分分析(PCA,降维),局部线性嵌入(LLE,降维) - 半监督学习:训练算法的数据中有大量不带标签数据加上小部分带标签数据,如
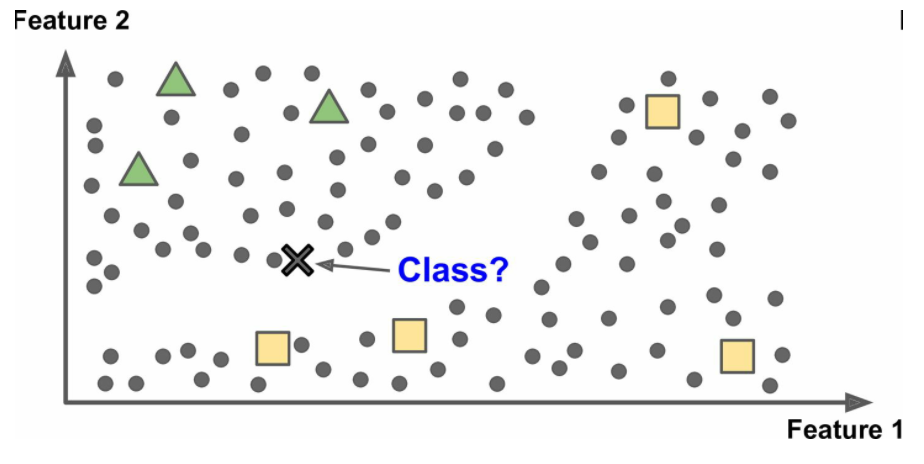
- 强化学习:学习系统在这里被称为智能体(agent),可以对环境进行观察,选择和执行动作,获得奖励(负奖励是惩罚,见图 1-12)。然后它必须自己学习哪个是最佳方法(称为策略,policy),以得到长久的最大奖励。策略决定了智能体在给定情况下应该采取的行动,如
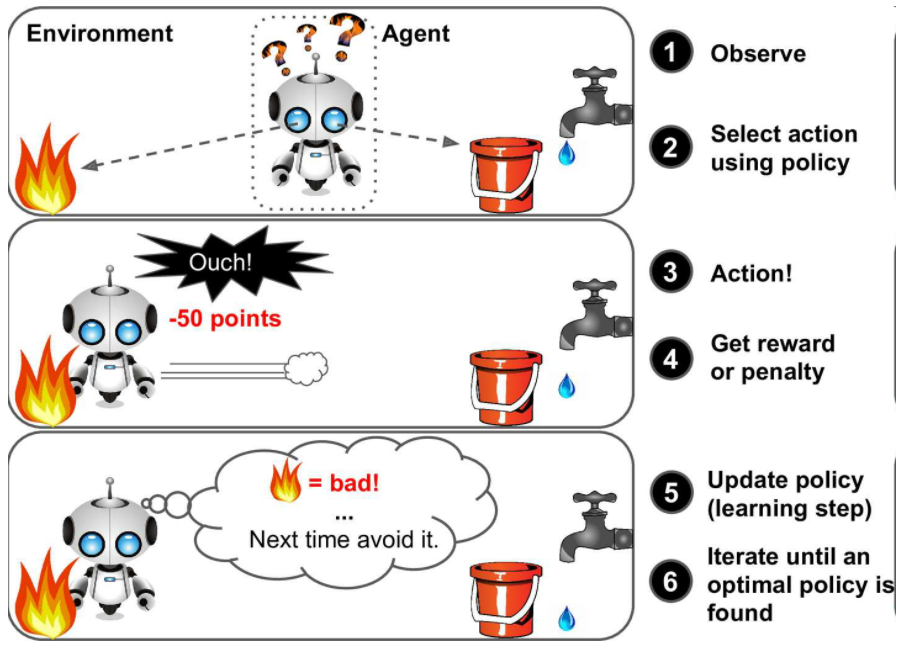
强化学习