本文主要记录《机器学习实战》中的理论知识拓展和实践问题中解决方案的总结

大纲
- 算法概念
- 简单数据集的KNN
- 约会数据集(实际数据)的KNN
- 手写识别数据集(测试集与预测集不同)的KNN
概念
K最近邻(k-Nearest Neighbor,KNN)分类算法:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。通俗来讲就是基于已经分好类的邻居,若是这个样本的K个最邻近的邻居多数输入某一类,则这个样本也属于这一类。
简单的数据集进行测试算法
首先先创建一些简单的数据集1
2
3
4
5
6
7
8
9
10
11
12
13from numpy import *
import operator
# 创建一些简单数据进行测试算法
def creatDataSet():
# 特征
group=array([[1.0,1.1],
[1.0,1.0],
[0,0],
[0,0.1]])
# 标签(分类)
labels=['A','A','B','B']
return group,labels
然后编写KNN算法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31# 对输入样本进行KNN分类
# 步骤:计算距离-选择距离最小的K个点-返回最多的分类
def classifify0(inX,dataSet,labels,k):
# 计算距离:使用欧式公式
dataSetSize=dataSet.shape[0]
# tile(A,(m,n))函数用于将数组A延长n倍重复m次构造成新的数组
# 例如tile(A,(3,2)),得到[[A,A],[A,A],[A,A]]
diffMat=tile(inX,(dataSetSize,1))-dataSet
sqDiffMat=diffMat**2
# sum(axis=1)将矩阵每一行向量相加
sqDistances=sqDiffMat.sum(axis=1)
distances=sqDistances**0.5
# A.argsort()返回将数组A中元素从小到大排序后的索引值
sortDiantances=distances.argsort()
classCount={}
for i in range(k):
label=labels[sortDiantances[i]]
# 字典get(key,default) 返回key对应的value,若没有key则返回default
# 使用这个函数的好处是不需要使用if判断
classCount[label]=classCount.get(label,0)+1
# 返回最多的分类
count=0
maxLabel=''
for key in classCount:
num=classCount[key]
if(num>count):
count=num
maxLabel=key
return maxLabel
开始简单地测试一下在简单数据集下的KNN算法分类1
2
3
4
5if __name__ == "__main__":
# 简单的K邻近算法
dataSet,labels=creatDataSet()
predictLebel=classifify0([1.2,1.2],dataSet,labels,3)
print(predictLebel)
运行查看结果
使用约会数据集预测结果评估KNN分类器的准确率
首先读入约会数据集1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24# KNN约会网站配对(根据3种特征将约会对象分成3类)
# 导入数据并解析成相应格式(数据集和标签)
def fileToDataSet(fileName):
fr=open(fileName)
# readlines()读取所有数据,每行以字符串的列表形式返回
allRow=fr.readlines()
numOfRow=len(allRow) # 返回列表长度,即数据行数
dataSet=zeros((numOfRow,3))
labels=[]
# 处理每一行数据
index=0
for row in allRow:
# 去除字符串首尾的空白字符(如' '、\t、\n等)
row=row.strip()
# 以\t作为分隔符分隔字符串
rowList=row.split('\t')
# 将每一行数据的前三个数据作为数据集
dataSet[index,:]=rowList[0:3]
# 将每一行数据的最后一个数据作为标签
labels.append(int(rowList[-1])) # append需要指定int否则默认字符串处理
index+=1
return dataSet,labels
由于每个特征的数据的范围不同,因此需要将特征值归一化处理1
2
3
4
5
6
7
8
9
10
11
12# 归一化数据(将所有特征值转化0-1区间的值)
def normalizeData(dataSet):
# 返回数据中每一列的最小值
minVal=dataSet.min(0)
maxVal=dataSet.max(0)
range=maxVal-minVal
normalDataSet=zeros(shape(dataSet))
numRow=dataSet.shape[0]
# 处理公式:value=(value-min)/(max-min)
normalDataSet=dataSet-tile(minVal,(numRow,1))
normalDataSet=normalDataSet/tile(range,(numRow,1))
return normalDataSet
将约会数据集作为训练集,再将每条约会数据集作为测试数据对KNN分类器的准确性进行测试1
2
3
4
5
6
7
8
9if __name__ == "__main__":
# 约会数据测试KNN准确率
errorNum=0.0;
for index in range(len(normalDateDataSet)):
predictLabel=classifify0(normalDateDataSet[index],normalDateDataSet,dateLabels,3)
if(predictLabel!=dateLabels[index]):errorNum+=1.0
print('predictLabel is '+str(predictLabel)+', the real label is '+str(dateLabels[index]))
errorRate=errorNum/float(len(normalDateDataSet))
print('the total error rate is '+str(errorRate))
运行查看结果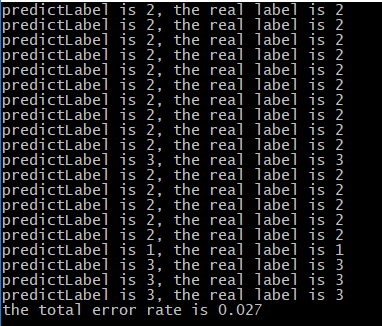
可以看到KNN分类器预测的准确性还是很高的,但由于是训练集与测试集是同一个,所以并不能准确地知道KNN分类器算法的精确度,我们可以尝试使用不同的训练集和测试集
手写识别数据集、不同测试集和训练集评估KNN分类器的准确率
首先查看下手写识别数据集
可以看到是一个使用二进制的32*32的文本文件
我们可以将其转为1*1024后每一位作为一个特征进行测试1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24# 手写识别(根据传入的32*32的二进制图像预测未知图像的数字0-9)即1024特征10个标签
# 将传入的32*32的二进制图像转为1*1024的特征
def imgToVector(fileName):
fr=open(fileName)
Vector=zeros((1,1024))
for i in range(32):
row=fr.readline()
for j in range(32):
Vector[0,32*i+j]=int(row[j])
return Vector
# 将传入的目录中的所有文件转换成数据集
def imgFileToDataSet(dicName):
# 获取目录中文件名和文件个数
trainDic=listdir(dicName)
numFile=len(trainDic)
dataSet=zeros((numFile,1024))
lebel=[]
# 将所有文件转成特征矩阵 文件名处理后为标签
for i in range(numFile):
fileName=trainDic[i]
dataSet[i,:]=imgToVector(str(dicName)+'/'+str(fileName))
fileStr=int(fileName.split('_')[0])
lebel.append(fileStr)
return dataSet,lebel
由于这次训练集与测试集不是同一个文件,因此需要分别读入,之后将测试集中的每个文件用训练集的KNN分类器分类预测标签再与测试集中真实标签进行对比,测试KNN分类器的准确度1
2
3
4
5
6
7
8
9
10
11
12
13if __name__ == "__main__":
# 手写识别
trainDataSet,trainLebel=imgFileToDataSet('trainingDigits')
testDataSet,testLebel=imgFileToDataSet('testDigits')
# 手写识别测试KNN准确率
errorNum=0.0;
for index in range(len(testDataSet)):
predictLabel=classifify0(testDataSet[index],trainDataSet,trainLebel,3)
if(predictLabel!=testLebel[index]):errorNum+=1.0
print('predictLabel is '+str(predictLabel)+', the real label is '+str(testLebel[index]))
errorRate=errorNum/float(len(testDataSet))
print('the total error rate is '+str(errorRate))
运行查看结果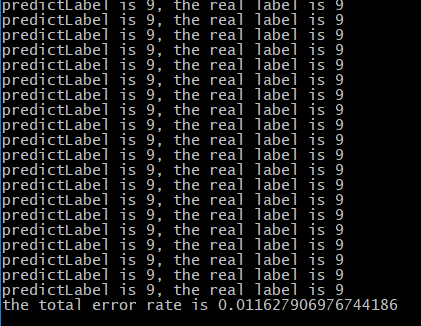
由于数据较多,特征也有1024项,因此计算较慢,运行结果来看KNN分类器的预测准确度还是蛮高的