本文记录Scrapy爬虫在Linux系统下的实战

大纲
scrapy startproject projectname
1.创建项目:scrapy startproject demo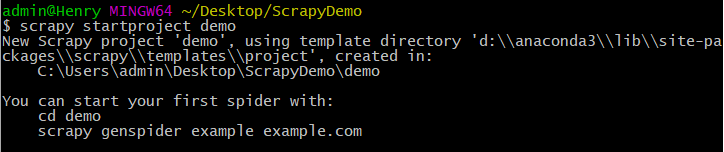
2.项目结构和文件作用:
用户编写的主要就是spiders+items+pipeline模块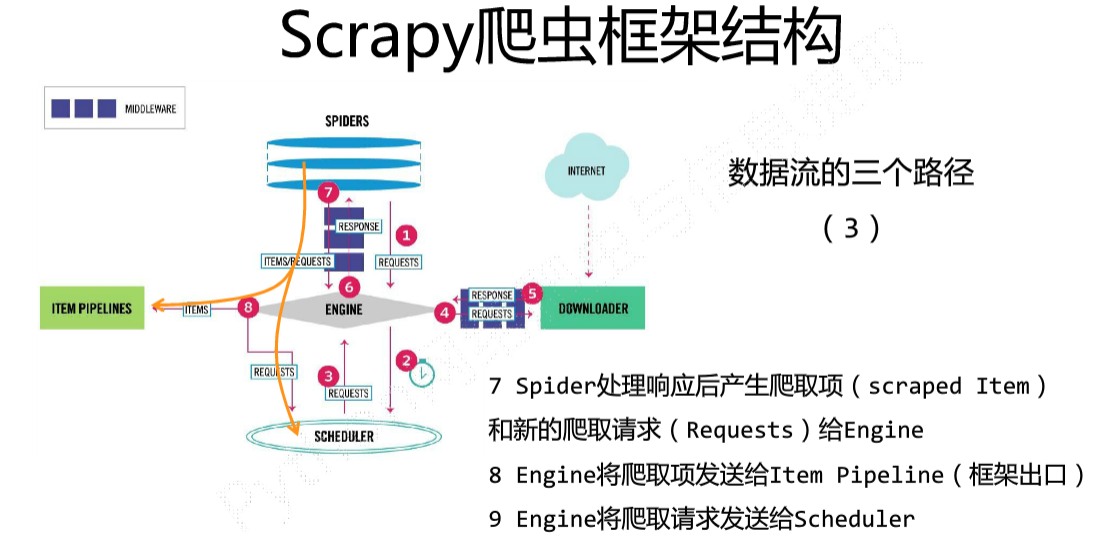
编写爬虫前的设置(settings.py)
1.设置爬虫不遵守robots.txt,robots协议就是网站规定的爬虫爬取规则1
2# Obey robots.txt rules
ROBOTSTXT_OBEY = False
2.设置取消Cookies,Cookies是服务器识别计算机的资料1
2# Disable cookies (enabled by default)
COOKIES_ENABLED = False
3.设置用户代理(USER_AGENT),可在浏览器F12-Network-Headers里找到浏览器代理,让爬虫伪装成浏览器1
2# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'
4.设置IP地址,一般来说有些网站被同一个IP访问过于频繁多次会封锁IP,这时候需要更换代理IP继续爬取
编写items模块
items模块主要定义爬取的数据字典1
2
3
4
5
6
7
8
9
10import scrapy
class DemoItem(scrapy.Item):
url=scrapy.Field()
title = scrapy.Field()
time = scrapy.Field()
source = scrapy.Field()
img=scrapy.Field()
content=scrapy.Field()
pass
编写spiders模块
1.新建爬虫文件:1
scrapy genspider -t basic spiderName spiderUrl
这里以爬取虎扑新闻(https://voice.hupu.com/nba/ )为例,则新建爬虫可以为scrapy genspider -t basic hupu hupu.com
2.编写爬虫文件
2.1爬取所有页面整体1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17class HupuSpider(scrapy.Spider):
name = 'hupu'
allowed_domains = ['hupu.com']
start_urls = ['http://hupu.com/']
# 规定爬取的url后会进入parse回调函数
def parse(self, response):
# 观察新闻每个页数的url,我们可以发现规律为
# 页数i对应的url为https://voice.hupu.com/nba/i
for i in range(0,1):
url='https://voice.hupu.com/nba/'+str(i+1)
# yield类似于这个数的return后循环在下一个数执行
# Request(url,callback)用于迭代爬取 可以调用callback进一步爬取传入的url
# 记得引入from scrapy.http import Request
# 这个语句的意思是 将每个遍历到的url做进一步处理再执行下一个遍历到的url
yield Request(url=url,callback=self.newsPage)
pass
2.1爬取每个页面需要的内容1
2
3
4
5
6
7
8
9
10
11# 上一个Request传入的url响应的response作为参数传入回调函数newsPage
def newsPage(self,response):
# 通过观察页面我们知道每个页面中的新闻的连接在
# 属性为class=list-hd的div标签下的h4标签下的a标签下的href属性中
# 可用response.xpath().extract()得到这个页面所有新闻的url
allPageUrl=response.xpath('//div[@class="list-hd"]/h4/a/@href').extract()
for i in range(0,len(allPageUrl)): #len(allPageUrl)
# 同样地 将这个页面的url一个一个遍历处理
yield Request(url=allPageUrl[i],callback=self.aNewPage)
pass
pass
2.1爬取每个新闻详情页面的信息1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16 # 上一个Request传入的每个新闻的url的响应response即新闻详情页面传入
def aNewPage(self,response):
# 此时要将爬取到的数据存入item中了
# 引入from news.items import NewsItem 新建item对象
item=NewsItem()
# 观察页面中所需信息的xpath信息再利用xpath存入对应的item字段
item['url']=[response.url]
item['title']=response.xpath('//div[@class="artical-title"]/h1/text()').extract()
item['time']=response.xpath('//div[@class="artical-info"]/span/a/span/text()').extract()
item['source']=response.xpath('//div[@class="artical-info"]/span/span/a/text()').extract()
item['img']=response.xpath('//div[@class="artical-importantPic"]/img/@src').extract()
content=response.xpath('//div[@class="artical-main-content"]//p/text()').extract()
# 注意爬取到的content为多段<p>标签组成 需要合并处理
item['content']=["\n".join(content)]
# 爬取到的数据交给pipelines处理
yield item
编写pipelines模块
pipeline主要功能为读取item中爬取到的数据+做相应数据处理+保存数据(数据库/文件/..)
1.读取item中爬取到的数据:1
2
3
4
5
6
7
8class NewsPipeline(object):
def process_item(self, item, spider):
url = item['url'][0]
title = item['title'][0]
timeT = item['time'][0]
source = item['source'][0]
img = item['img'][0]
content = item['content']
2.数据处理:1
2
3
4
5
6
7# 如title中有杂乱的空格和\r\n数据
title = title.replace(' ','').replace('\r\n','')
# 如需要将时间转换成时间戳存储
from datetime import datetime
import time
datetimeTime=datetime.strptime(str(timeT).replace(' ',''), '%Y-%m-%d%H:%M:%S')
timestampTime=time.mktime(datetimeTime.timetuple())
3.保存数据至数据库:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50# python操作数据库模块
import pymysql
# 数据库连接参数
config={
'host':'127.0.0.1',
'port':3306,
'user':'root',
'password':'',
'db':'news',
'charset':'utf8'
}
class NewsPipeline(object):
# 连接数据库
def __init__(self):
self.conn=pymysql.connect(**config)
def process_item(self, item, spider):
try:
url = item['url'][0]
title = item['title'][0].replace(' ','').replace('\r\n','')
timeT = item['time'][0]
source = item['source'][0]
img = item['img'][0]
content = item['content']
# 时间转成时间戳存储
# str->datetime 字符串转datetime格式
datetimeTime=datetime.strptime(str(timeT).replace(' ',''), '%Y-%m-%d%H:%M:%S')
#datetime->timestamp datetime格式转timestamp格式
timestampTime=time.mktime(datetimeTime.timetuple())
print('----------start--------\n')
# 初始化游标用于存储数据
cursor=self.conn.cursor()
sql='INSERT INTO news (url,title,time,source,img,content) VALUES (%s,%s,%s,%s,%s,%s)'
cursor.execute(sql,(url,title,timestampTime,source,img,content))
self.conn.commit()
print('新闻链接:', url)
print('新闻标题:', title)
print('----------end--------\n')
return item
except Exception as err:
# 存储失败打印错误信息
print(str(err))
pass
# 关闭游标和数据库
def close_spider(self):
cursor.close()
self.conn.close()
编写自动化脚本周期执行爬虫
1.编写自动化脚本:
在linux下执行的python文件需要指定执行.py文件的python路径,可用which python命令找到路径,写在.py文件顶部,如#!/usr/bin/python1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19#!/usr/bin/python
import time
import os
# 循环执行
while True:
print time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
print("---------Run Scrapy!-----------")
# 发送系统指令 执行爬虫命令就是scrapy crawl hupu --nolog
os.system("scrapy crawl hupu --nolog")
print("---------End Scrapy!-----------")
# 执行更新新闻脚本 在后续文件中
os.system("./updateNews.py")
# 规定脚本每执行一次阻塞10分钟 即每10分钟执行一次爬取
time.sleep(60*10)
2.编写自动化更新新闻(删除旧新闻)脚本1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35#!/usr/bin/python
import pymysql
import time
from datetime import datetime
from datetime import timedelta
config={
'host':'127.0.0.1',
'port':3306,
'user':'root',
'password':'123456',
'db':'news',
'charset':'utf8'
}
try:
conn=pymysql.connect(**config)
cursor=conn.cursor()
# 得到昨天此时的时间戳
lastday=datetime.now()-timedelta(days=1)
lastdayTimestamp=time.mktime(lastday.timetuple())
# 将时间戳小于昨天此时的时间戳的新闻删除
sql='DELETE FROM news WHERE news.time<'+str(lastdayTimestamp)
deleteCount=cursor.execute(sql)
conn.commit()
print('-----------DELETE OLD NEWS NUM:----------')
print(deleteCount)
print('---------------DELETE END--------------------')
except Exception as err:
print('DELETE FAIL MSG BEHIND:')
print(str(err))
pass
3.执行自动化脚本1
2
3
4
5
6
7
8
9# 若是windows编写的.py文件在linux下执行需要更改文件格式:
vim run.py
:set ff=unix
# 添加执行权限
chmod u+x run.py
# 在后台执行脚本并输出执行日志在脚本目录下
nohup ./run.py > nohup.log 2>&1 &
# 查看脚本是否执行
ps -ef|grep python