本文记录Scrapy爬虫在Linux系统下的实战

大纲
- CentOS7下安装Scrapy
- Scrapy命令
CentOS7下安装Scrapy
1.首先查看一下系统有无内置python和pip工具
可以看到CentOS7中是有内置Python2.7.5和pip9.0.1
Scrapy仅支持Python2.7以上或者Python3.3以上,那么CentOS7内置版本的Python已经足够了
2.安装gcc及扩展包
yum install gcc libffi-devel python-devel openssl-devel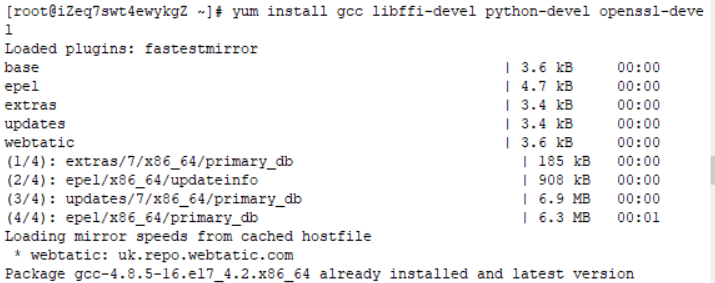
3.安装开发工具包
yum groupinstall -y development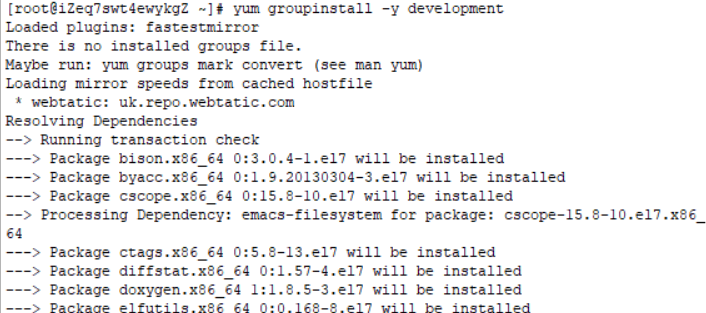
4.安装libxslt-devel支持lxml
yum install libxslt-devel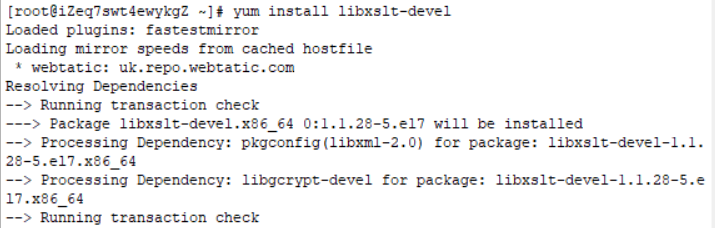
5.安装Scrapy
pip install scrapy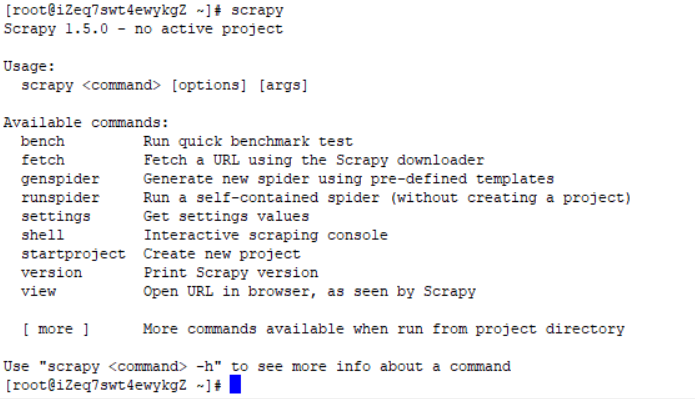
可以看到,安装成功了,至此Scrapy爬虫环境搭建就完成了
Scrapy命令
Scrapy命令分为全局命令和项目命令
全局命令:全局使用,主要用于整体项目
使用scrapy -h可以查看全局命令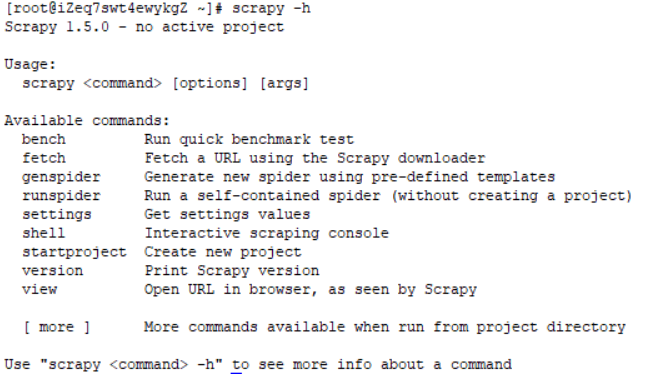

项目命令:进入项目内部使用
进入项目路径后执行scrapy-h可以看到项目命令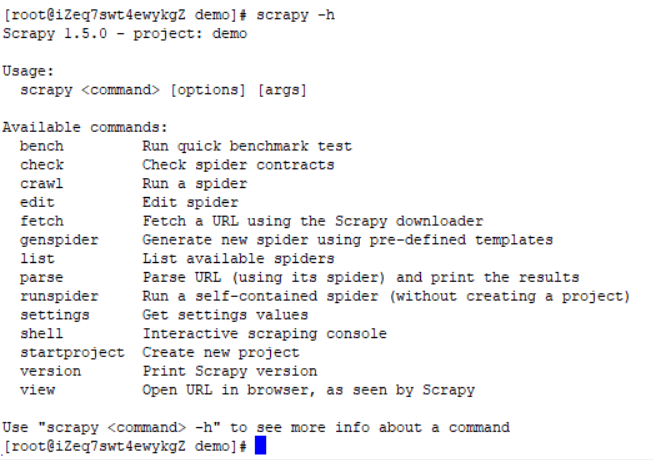

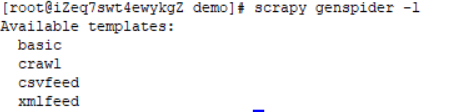
Tips:basic基础模板 crawl自动爬虫 csvfeed处理csv文件 xmlfeed处理xml文件,若用basic模板创建一个文件fileDemo则使用命令:scrapy genspider -t basic fileDemo创建一个fileDemo.py文件